Amazons Fire TV-Sticks sind eine günstige Möglichkeit, einen Fernseher in einen Smart TV auf Android-Basis zu verwandeln. Allerdings findet man nicht jede App, die man am Fire TV-Stick nützen möchte, in Amazons eigenem App Store. Hier zeige ich euch, wie ihr Apps sideloaden könnt. Dazu braucht ihr einen PC, der im selben WLAN hängt wie der Fire TV-Stick.
Den PC vorbereiten: Android Debug Bridge installieren
- Von der Android Developer-Website die platform-tools herunterladen.
- Die .zip-Datei in einen beliebigen Ordner am PC entpacken. Den Pfad zu diesem platform-tools-Ordner brauchen wir später noch.
Den Fire TV-Stick vorbereiten
- Für die Installation muss man am Fire TV-Stick die Entwickleroptionen aktivieren. In gewohnter Android-Manier ging das bei meinem Fire TV-Stick, indem ich im Menü Einstellungen > Mein Fire TV > Info siebenmal auf Fire TV Stick geklickt habe. Bei verschiedenen Versionen des Fire TV-Sticks geht das allerdings ein bisschen unterschiedlich. Amazon hat hier eine Anleitung dafür.
- Später werden die IP-Adresse des Sticks brauchen. Sie ist unter Einstellungen > Mein Fire TV > Info > Netzwerk zu finden.
- Im Menü Einstellungen > Mein Fire TV > Entwickleroptionen müssen wir ADB-Debugging und Apps unbekannter Herkunft einschalten.
Das APK finden und herunterladen
- Man besorge sich die gewünschte App als .apk-Datei aus einer vertrauenswürdigen Quelle. Für diesen Blogpost lade ich eine Version von NewPipe aus dem F-Droid Appstore herunter.
- Der Einfachheit halber schiebt man die .apk-Datei in den platform-tools-Ordner.
Die App installieren
- Eine Shell (Eingabeaufforderung) starten: Windows-Taste drücken, „cmd“ eintippen und Enter drücken oder Öffnen klicken.
- In den platform-tools-Ordner wechseln:
cd (Pfad)
Also zum Beispiel:
cd C:\platform-tools - Die Android Debug Bridge mit dem Fire TV-Stick verbinden:
.\adb connect (IP-Adresse):5555
Also zum Beispiel:
.\adb connect 10.0.0.11:5555 - Der Fire TV-Stick zeigt nun auf dem Fernseher einen Dialog USB-Debugging zulassen an. Das bestätigt man. In der Shell bekommt man die Meldung
failed to authenticate to 10.0.0.11:5555 - Den Befehl aus Schritt 3 wiederholen. Nun bekommt man die Meldung
already connected to 10.0.0.11:5555. - Nun können wir die APK-Datei installieren:
.\adb install (Dateiname.apk)
Also zum Beispiel:
.\adb install .\org.schabi.newpipe_1010_cb84069.apk
In der Shell bekommen wir eine Rückmeldung:Performing Push Install
.\org.schabi.newpipe_1010_cb84069.apk: 1 file pushed, 0 skipped. 0.4 MB/s (10881466 bytes in 25.386s)
pkg: /data/local/tmp/org.schabi.newpipe_1010_cb84069.apk
Success
Falls in der letzten Zeile nicht Success steht, hat irgendwas nicht geklappt. Möglicherweise ist die App nicht mit der Abdroid-Version des Fire TV-Sticks kompatibel. - Nach der Installation trennt man die Android Debug Bridge vom Fire TV-Stick:
adb disconnect
Nachbereitung
- Die App ist nun im Menü Meine Apps des Fire TV-Sticks sichtbar. Wenn man möchte, kann man sie von dort auf die Startseite verschieben.
- An dieser Stelle ist es auch nicht blöd, in den Entwickleroptionen ADB Debugging zulassen und Apps unbekannter Herkunft wieder abzuschalten.
- Die installierte .apk-Datei kann man aus dem Ordner platform-tools löschen.
App updaten
Um eine bereits installierte App upzudaten, muss man die Prozedur wiederholen. Es ist daher sinnvoll, sich den Ordner mit den platform-tools zu behalten.


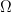 an.
an. zwischen dem Scheinwerfer und der Wand sowie die Größe des beleuchteten Flecks
zwischen dem Scheinwerfer und der Wand sowie die Größe des beleuchteten Flecks  . Um uns das Leben einfacher zu machen, verwenden wir für
. Um uns das Leben einfacher zu machen, verwenden wir für  ,
,  und
und 
 (in Lumen) in die Lichtstärke
(in Lumen) in die Lichtstärke  (in Candela) umrechnen:
(in Candela) umrechnen:

![\Phi_v = 300 \mathrm{[lm]}](https://s0.wp.com/latex.php?latex=%5CPhi_v+%3D+300+%5Cmathrm%7B%5Blm%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) und produziert in
und produziert in ![r = 1.2 \mathrm{[m]}](https://s0.wp.com/latex.php?latex=r+%3D+1.2+%5Cmathrm%7B%5Bm%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) Entfernung einen Lichtschein mit
Entfernung einen Lichtschein mit ![a \times b = 0.7 \mathrm{[m]} \times 0.5 \mathrm{[m]} = 0.35 \mathrm{[m^2]}](https://s0.wp.com/latex.php?latex=a+%5Ctimes+b+%3D+0.7+%5Cmathrm%7B%5Bm%5D%7D+%5Ctimes+0.5+%5Cmathrm%7B%5Bm%5D%7D+%3D+0.35+%5Cmathrm%7B%5Bm%5E2%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) . Damit ist der Raumwinkel
. Damit ist der Raumwinkel  und die Lichtstärke
und die Lichtstärke ![I_v = (300 \mathrm{[lm]})/(0.24) = 1250 \mathrm{[cd]}](https://s0.wp.com/latex.php?latex=I_v+%3D+%28300+%5Cmathrm%7B%5Blm%5D%7D%29%2F%280.24%29+%3D+1250+%5Cmathrm%7B%5Bcd%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) . Das ist sehr deutlich mehr als die vom Gesetzgeber geforderten 100 cd, und damit ist der Scheinwerfer hell genug.
. Das ist sehr deutlich mehr als die vom Gesetzgeber geforderten 100 cd, und damit ist der Scheinwerfer hell genug. (das entspricht einer halben Kugeloberfläche). Der notwendige Lichtstrom ist dann
(das entspricht einer halben Kugeloberfläche). Der notwendige Lichtstrom ist dann ![\Phi_v = I_v \times \Omega = 1 \mathrm{[cd]} \times 2 \pi = 6.28 \mathrm{[lm]}](https://s0.wp.com/latex.php?latex=%5CPhi_v+%3D+I_v+%5Ctimes+%5COmega+%3D+1+%5Cmathrm%7B%5Bcd%5D%7D+%5Ctimes+2+%5Cpi+%3D+6.28+%5Cmathrm%7B%5Blm%5D%7D&bg=ffffff&fg=000&s=0&c=20201002) . Das klingt nach wenig, aber man findet im Handel durchaus auch Rücklichter mit bloß 4 Lumen. Bei diesen muss man darauf achten, ob sie in einen etwas geringeren Raumwinkel strahlen.
. Das klingt nach wenig, aber man findet im Handel durchaus auch Rücklichter mit bloß 4 Lumen. Bei diesen muss man darauf achten, ob sie in einen etwas geringeren Raumwinkel strahlen.
